JDBC
本文最后更新于:2023年1月20日 凌晨
JDBC
什么是JDBC?
JDBC就是使用Java语言操作关系型数据库的一套API,全称(Java DataBase Connectivity)Java数据库连接。
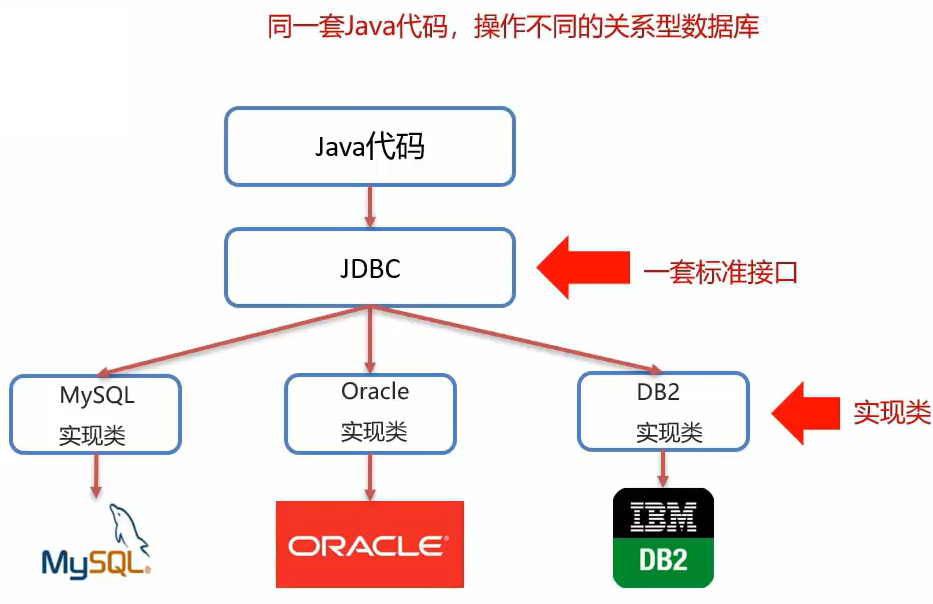
- 官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口。
- 各个数据库厂商去实现这套接口,提供数据库驱动jar包。
- 我们可以使用这套接口(JDBC) 编程,真正执行的代码是驱动jar包中的实现类。
如何使用JDBC?
1.配置JDBC环境,即MySQL连接驱动:
<!--数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>2.创建示例数据库:
create database db1;
create table account(
`id` int primary key,
`name` varchar(4) not null,
`money` int not null
);
Insert into account values (1,"ming",10000);3.编写JDBC代码:
public class Main {
public static void main(String[] args) throws Exception {
//1.注册驱动(这一步可以省略,具体原因可看下面的API详解)
Class.forName("com.mysql.jdbc.Driver");//固定的包名,较新版本的为 com.mysql.cj.jdbc.Driver
//2.获取连接
String url = "jdbc:mysql://127.0.0.1:3306/db1";//"jdbc:mysql://+IP+ Port/数据库名"
String username = "root";
String password = "123";
Connection connection = DriverManager.getConnection(url, username, password);
//3.定义sql语句
String sql = "update account set money =20300 where id =1";
//4.获取执行sql的对象 statement
Statement statement = connection.createStatement();
//5.使用 statement 对象执行sql
int count = statement.executeUpdate(sql);//返回受影响的行数
//6.处理返回结果
System.out.println(count);
//7.释放资源
statement.close();
connection.close();
}
}JDBC相关类详解
Drivermanager
Drivermanager是驱动管理类,其作用如下:
1.注册驱动
告诉程序该使用哪一个数据库驱动jar
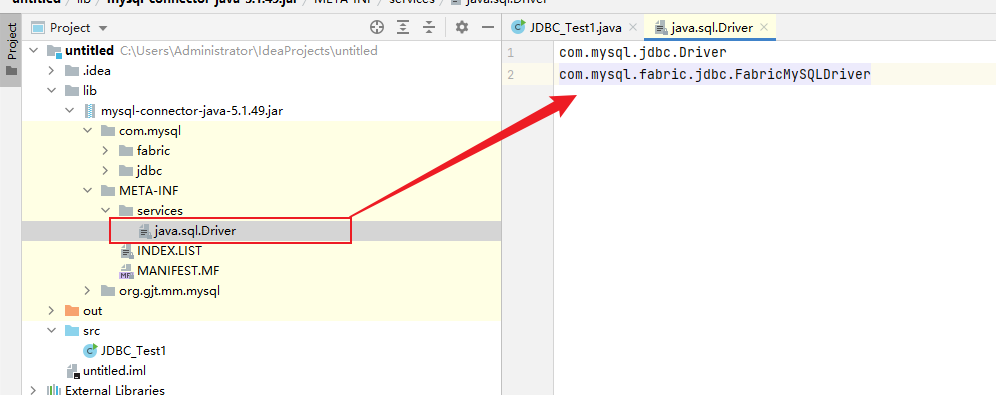
Class.forName("com.mysql.jdbc.Driver");MySQL5之后的驱动包可以省略注册驱动的步骤,其会自动加载jar包中的META-INF/services/java.sql.Driver文件中的驱动类。
2.获取数据库连接
static Connection getConnection(String url, String user, String password)- url:
jdbc:mysql://ip地址(域名):端口号/数据库名称?参数键对值1?参数键对值2... - user:用户名
- password:密码
如果是连接本机mysql,并且mysql默认端口是3306,则可以省略IP地址和端口:
"jdbc:mysql:///mybatis?serverTimezone=UTC&?useSSL=false";//省略127.0.0.1:3306当版本达到 5.7 及以上,MySQL会建议你使用更为安全的 SSL
连接,这种连接需要复杂的配置,而且会降低20%的性能,所以我们通常不使用这种配置,并设置参数关闭其警告提示——?useSSL=false。(在xml文件中配置要使用转义字符转义?,如&useSSL=false)
"jdbc:mysql://127.0.0.1:3306/db1?useSSL=false";Connection
Connection是数据库连接对象,用于接收数据库的连接。
1.获取执行SQL的对象
Statement createStatement();//普通SQL的执行对象
PreparedStatement prepareStatement(String sql);//预编译SQL的执行对象
CallableStatement prepareCall(String sql);//存储过程的执行对象主要使用前两种,第三种很少用
2.管理事务
| MySQL事务管理 | JDBC事务管理 | |
|---|---|---|
| 备注 | MySQL默认自动提交事务 | Connection接口定义了三个管理事务的方法 |
| 开启事务 | BEGIN;/START TRANSACTION | setAutoCommit(boolean auto Commit) |
| 提交事务 | COMMIT | commit() |
| 回滚事务 | ROLLBACK | rollback() |
示例数据库:
CREATE DATABASE IF NOT EXISTS db1;
USE db1;
CREATE TABLE account ( `id` INT, `name` VARCHAR ( 10 ), `money` INT, PRIMARY KEY ( id ) );
INSERT INTO account VALUES (1,"阿画",20);
INSERT INTO account VALUES (2,"苗苗",5000);示例代码:
public class Main {
public static void main(String[] args) throws Exception {
//1.获取连接
String url = "jdbc:mysql:///db1";//jdbc:mysql://+ IP + Port /数据库名
String username = "root";
String password = "123";
Connection connection = DriverManager.getConnection(url, username, password);
//2.定义sql语句
String sql1 = "update account set money =money+500 where id =1";
String sql2 = "update account set money =money-500 where id =2";
//3.获取执行sql的对象 statement
Statement statement = connection.createStatement();
/*----------事务管理演示----------*/
try {
//将自动提交事务关闭,即开启事务
connection.setAutoCommit(false);
//执行sql
int count1 = statement.executeUpdate(sql1);//返回受影响的行数
System.out.println(count1);
//出现意外,直接跳到异常catch代码块,执行回滚事务
// System.out.println(3 / 0);
int count2 = statement.executeUpdate(sql2);//返回受影响的行数
System.out.println(count2);
//提交事务
connection.commit();
} catch (SQLException e) {
//回滚事务
connection.rollback();
e.printStackTrace();
}
//释放资源
statement.close();
connection.close();
}
}Statement
Statement接口提供了三种执行SQL的方法:executeQuery、executeUpdate、execute
1.执行DML、DDL
int executeUpdate(sql)返回DML语句影响的行数 (DDL语句执行后,比如创建数据库、表等执行成功 返回0),一般情况下我们不需要返回影响的行数,只需要知道执行是否成功,可以这样做:
- DML:返回的行数大于零即执行成功
- DDL:成功执行返回的也是0,此时可以认为不出现异常就算成功
2.执行DQL
ResultSet executeQuery(sql)返回结果集实例 ResultSet
ResultSet
ResultSet是结果集对象,用于存储DQL语句搜索的结果,其封装了二维表,内部存有游标,游标默认指向数据的上一行(即表头行)。
- 结果集在使用时不能关闭connection,否则无法操作
- 列号从1开始记录
boolen next();//判断数据是否存在,同时会将游标向下游动一行将光标从当前位置向下移动一行,判断当前行是否为有效行(即有数据的行),返回true则有数据,false则无数据
Xxx getXxx(int 列的编号 / String 列的名称 );//获取数据示例
public class Main {
public static void main(String[] args) throws SQLException {
//链接数据库
String url = "jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=false";
String user = "root";
String password = "123";
Connection connection = DriverManager.getConnection(url, user, password);
//执行SQL
Statement statement = connection.createStatement();
String sql = "select * from tb_user";
ResultSet resultSet = statement.executeQuery(sql);
//ResultSet操作
while (resultSet.next()) {
//列编号作参数
int id = resultSet.getInt(1);
String name = resultSet.getString(2);
int money = resultSet.getInt(3);
//列名作参数
// int id = resultSet.getInt("id");
// String name = resultSet.getString("name");
// int money = resultSet.getInt("money");
System.out.println(id + " " + name + " " + money);
}
}
}结果集通常和集合搭配使用:比如将ResultSet的数据封装进ArrayList<pojo>、Vector<pojo>…中
1.定义pojo类
2.将ResultSet的数据使用 setter() 装入pojo对象中,再将pojo对象装入集合容器中。
ResultSetMetaData
ResultSetMetaData 结果集的元数据
//获取结果集的元数据
ResultSetMetaData metaData = resultSet.getMetaData();
//获取属性个数
int column = metaData.getColumnCount();
//getColumnLabel获取的是select语句中的别名
String columnLabel = metaData.getColumnLabel(i);
//getColumnName获取的是select语句中的属性
String columnName = metaData.getColumnName(i);PreparedStatement
继承自 Statement,作用是预编译SQL语句并执行,可以预防SQL注入。
1.SQL注入介绍
SQL注入是对用户输入数据的合法性没有判断或过滤不严,通过操作输入来修改事先定义好的SQL语句,用以达到执行代码对服务器进行攻击的方法。
@Test
public void testLoginInject() throws Exception {
//获取连接
String url = "jdbc:mysql:///db1?serverTimezone=UTC";//jdbc:mysql://+ IP + Port /数据库名
String username = "root";
String password = "123";
Connection conn = DriverManager.getConnection(url, username, password);
String name = "dadsadadad";
String pwd = "' or '1' = '1";
String sql = "select * from tb_user where username='" + name + "'and password ='" + pwd + "'";
System.out.println(sql);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
if (rs.next()) {
System.out.println("login success");
} else {
System.out.println("login fail");
}
//释放资源
stmt.close();
conn.close();
}
数据库语句
CREATE TABLE `tb_user` (
`username` varchar(20) DEFAULT NULL,
`password` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;2.防止SQL注入
造成SQL注入的原因还是在拼接字符串时被钻了篡改语义的空子,所以PreparedStatement干脆不拼接字符串,直接使用?占位符代替参数值。
1.获取PreparedStatement对象
new Connection().prepareStatement(String sql)
//SQL语句中的参数值,这里使用?占位符替代
String sql = "select * from user where username = ? and password = ?";
//通过Connection对象获取获取,并传入对应的SQL语句
PreparedStatement pstmt = conn.prepareStatement(sql);2.设置参数值
使用?占位符代替参数拼接后,我们使用
setXxx(position,value)来设置参数:
参数1为 ?的位置编号,参数2为指定参数的值
String sql = "UPDATE person SET salary = ? WHERE name = ?";//设置了两个参数
PreparedStatement pstmt = connection.preparedStatement(sql);
//为两个参数赋值并执行
pstmt.setInt(1,5000);//第1个位置 value = 5000
pstmt.setString(2,"zhangsan");//第2个位置 value = "zhangsan"
pstmt.executeUpdate();3.执行SQL,不需要再传递sql,直接使用PreparedStatement对象调用,
pstmt.executeUpdate();
pstmt.executeQuery();
@Test
public void testLogin_Inject() throws Exception {
//获取连接
String url = "jdbc:mysql:///db1?serverTimezone=UTC";//jdbc:mysql://+ IP + Port /数据库名
String username = "root";
String password = "' or '1' ='1";//这里使用SQL注入也会失败
Connection conn = DriverManager.getConnection(url, username, password);
String name = "zhangsan";
String pwd = "1234";
String sql = "select * from tb_user where username=? and password = ?";
PreparedStatement pstmt = conn.prepareStatement(sql);
//设置?的值
pstmt.setString(1, name);
pstmt.setString(2, pwd);
ResultSet rs = pstmt.executeQuery();
if (rs.next()) {
System.out.println("登录成功");
} else {
System.out.println("登录失败");
}
//释放资源
rs.close();
pstmt.close();
conn.close();
}预防机制原理:
在设置?的值时会对其转义,原本的单引号'会被转义为\',即原本的SQL注入就变成了'\' or \'1\' =\'1\',无法起到原先的作用。
3.预编译SQL
PreparedStatement能预编译SQL,提高性能。
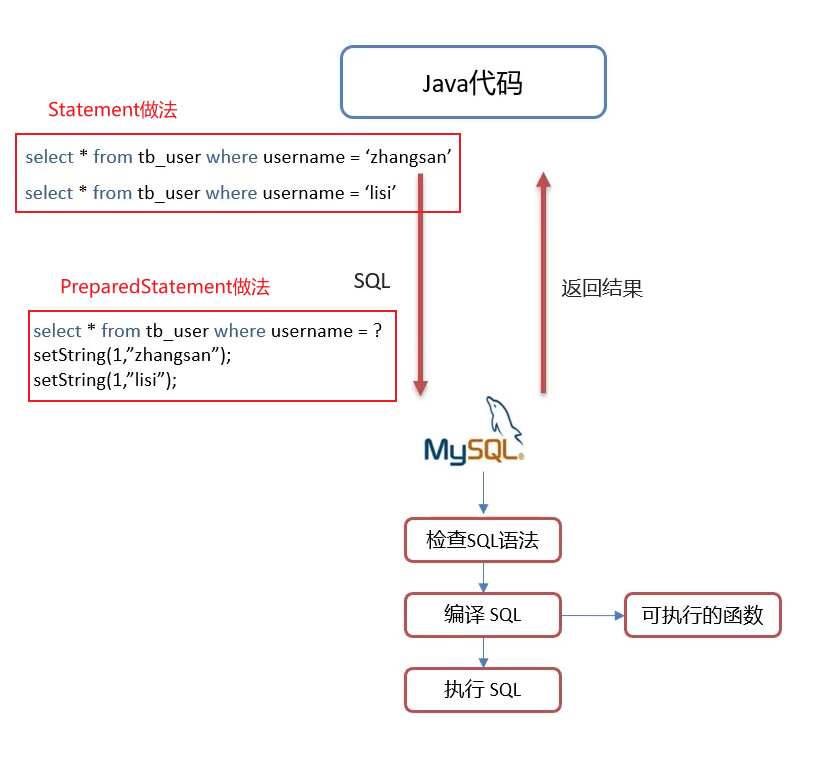
- 当我们在Java中写完SQL语句后,Java代码会将SQL传给MySQL进行检查SQL语法和编译SQL,这两步的执行时间比执行SQL可能更久。
- 对于Statement对象来说,要执行SQL语句需要每次将其导入Statement对象,如上图,MySQL会分别对两句SQL进行检查和编译;
- 而对于PreparedStatement对象来说,MySQL只会对SQL语句检查、编译一次,如果sql模板一样,则只需要进行一次检查、编译。
PreparedStatement预编译功能开启:在url后加
useServerPrepStmts=trueString url = "jdbc:mysql:///db1?serverTimezone=UTC&useServerPrepStmts=true";配置MySQL执行日志(重启mysq|服务后生效)
log-output=FILE general-log=1 general_log_file="D:\mysql.log" #日志的位置 slow-query-log=1 slow_query_log_file="D:\mysql_slow.log" long_query_time=2
使用之前的SQL注入测试,SQL注入问题解决

数据库连接池
- 数据库连接池是个容器(集合),负责存放、分配、管理数据库连接
- 它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏
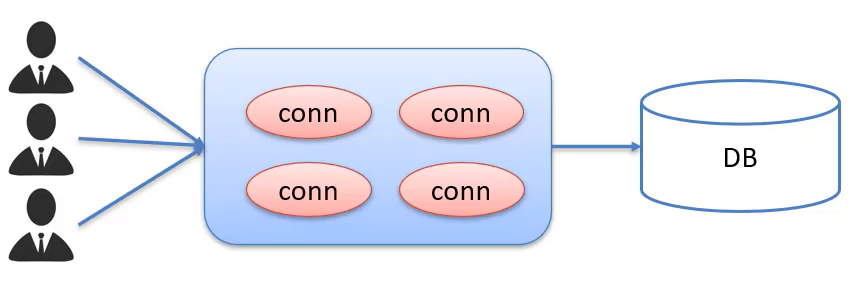
官方(SUN)提供的数据库连接池标准接口DataSource,由第三方组织实现此接口,其功能是获取连接。常见的数据库连接池:DBCP、C3PO、Druid.
使用Druid
Druid(德鲁伊)连接池是阿里巴巴开源的数据库连接池项目,功能强大,性能优秀,是Java语言最好的数据库连接池之一。
1.配置环境,导入Maven依赖:
<!-- Druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.9</version>
</dependency>
<!--MySQL8驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>2.定义配置文件 druid.properties
#druid.properties
#数据库连接驱动
driverClassName=com.mysql.cj.jdbc.Driver
#数据库连接信息
#url数据库的jdbc连接地址。一般为连接oracle/mysql。示例如下:
#1、mysql : jdbc:mysql://ip:port/dbname?option1&option2&…
#2、oracle : jdbc:oracle:thin:@ip:port:oracle_sid
url=jdbc:mysql:///mybatis?useSSL=false&serverTimezone=Asia/Shanghai
username=root
password=123
#初始化连接数量 (10-50已足够)
initialSize=5
#最大连接数 (连接池中最多支持多少个活动会话)
maxActive=10
#最大等待时间,单位为毫秒,超过maxWait的值后,认为本次请求失败,即连接池没有可用连接,设置-1时表示无限等待,建议设置为100
maxWait=30003.编码使用
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.Connection;
import java.util.Properties;
/**
* @author agust
*/
public class DruidTest {
public static void main(String[] args) {
//1.加载配置文件
Properties properties = new Properties();
try {
properties.load(new FileInputStream("src/main/resources/druid.properties"));
} catch (IOException e) {
e.printStackTrace();
}
//2.获取连接池对象
DataSource dataSource = null;
Connection connection = null;
try {
dataSource = DruidDataSourceFactory.createDataSource(properties);
//3.获取数据库连接
connection = dataSource.getConnection();
} catch (Exception e) {
e.printStackTrace();
}
//执行后续操作...
System.out.println(connection);
}
}使用CP30
性能一般
1.导入环境 c3p0-0.9.5.2.jar 和
mchange-commons-java-0.2.12.jar
<!-- c3p0数据库连接池 -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.5</version>
</dependency>
<!-- mchange-commons-java -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>mchange-commons-java</artifactId>
<version>0.2.20</version>
</dependency>2.定义配置文件:c3p0.properties 或者 c3p0-config.xml
<?xml version="1.0" encoding="utf-8" ?>
<!-- c3p0-config.xml -->
<c3p0-config>
<!-- 使用默认的配置读取连接池对象 -->
<default-config>
<!-- 连接参数 -->
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/db1</property>
<property name="user">root</property>
<property name="password">123</property>
<!-- 连接池参数 -->
<!--初始化申请的连接数量-->
<property name="initialPoolSize">5</property>
<!--最大的连接数量-->
<property name="maxPoolSize">10</property>
<!--超时时间-->
<property name="checkoutTimeout">3000</property>
</default-config>
<named-config name="otherc3p0">
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/db3</property>
<property name="user">root</property>
<property name="password">root</property>
<!-- 连接池参数 -->
<property name="initialPoolSize">5</property>
<property name="maxPoolSize">8</property>
<property name="checkoutTimeout">1000</property>
</named-config>
</c3p0-config>3.编码实现
import com.mchange.v2.c3p0.ComboPooledDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
/**
* @author agust
*/
public class C3p0Test {
public static void main(String[] args) {
//1.创建数据库连接池对象
DataSource ds = new ComboPooledDataSource();
//2. 获取连接对象
Connection conn = null;
try {
conn = ds.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println(conn);
}
}Spring JDBC
Spring框架对JDBC的简单封装。提供了一个JDBCTemplate对象简化JDBC的开发
- 获取JDBCTemplate:
JdbcTemplate template = new JdbcTemplate(dataSource); - 执行修改:
template.update() - 执行查找:
queryForMap(SQL语句,参数占位符内容...)queryForList(SQL语句,参数占位符内容...)query(SQL语句,new RowMapper<JavaBean>())query(SQL语句,new BeanPropertyRowMapper<>(JavaBean.class))queryForObject(SQL语句,JavaBean.class)
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.3.22</version>
</dependency>示例编码:
import com.alibaba.druid.pool.DruidDataSourceFactory;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
/**
* @author agust
* @date 2022/8/20
* @note Spring框架对JDBC的简单封装。提供了一个JDBCTemplate对象简化JDBC的开发
*/
public class SpringJdbc {
public static void main(String[] args) {
//1.加载配置信息,获取 DataSource
Properties properties = new Properties();
try {
properties.load(new FileInputStream("src/main/resources/druid.properties"));
} catch (IOException e) {
e.printStackTrace();
}
DataSource dataSource = null;
try {
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
//2.依赖于数据源 DataSource,.
// 获取 JdbcTemplate ,对数据库直接进行操作
JdbcTemplate template = new JdbcTemplate(dataSource);
/*
* update()
* 执行DML语句。增、删、改语句
*/
String sql1 = "Insert into student values (123,'agust',22)";
template.update(sql1);
sql1 = "delete from student where sno = 123";
template.update(sql1);
/*
* queryForMap(SQL语句,参数占位符内容...)
* 查询结果将结果集封装为map集合,将列名作为key,将值作为value 将这条记录封装为一个map集合
* 注意:这个方法查询的结果集长度只能是1,若查出的结果集大于1则会报错
*/
String sql2 = "select * from student where sage = ?";
System.out.println("-------------" + sql2 + "-------------");
Map<String, Object> map = template.queryForMap(sql2, 99);
Set<Map.Entry<String, Object>> entries = map.entrySet();
entries.forEach(entry -> {
String key = entry.getKey();
Object value = entry.getValue();
System.out.println(key + ":" + value);
});
/*
* queryForList()
* 查询结果将结果集封装为list集合
* 注意:将每一条记录封装为一个Map集合,再将Map集合装载到List集合中
*/
String sql3 = "select * from student where sage < 99";
System.out.println("-------------" + sql3 + "-------------");
List<Map<String, Object>> maps = template.queryForList(sql3);
for (int i = 0; i < maps.size(); i++) {
Map<String, Object> map1 = maps.get(i);
map1.forEach((s, o) -> System.out.println(s + ":" + o));
System.out.println();
}
/* query():查询结果,将结果封装为JavaBean对象
* query的参数:RowMapper
* 一般我们使用BeanPropertyRowMapper实现类。可以完成数据到JavaBean的自动封装
* new BeanPropertyRowMapper<类型>(类型.class)
*/
String sql4 = "select * from student";
System.out.println("-------------" + sql4 + "-------------");
List<Student> query = template.query(sql4, new RowMapper<Student>() {
@Override
public Student mapRow(ResultSet rs, int rowNum) throws SQLException {
String sno = rs.getString("sno");
String sname = rs.getString("sname");
int sage = rs.getInt("sage");
Student student = new Student();
student.setSno(sno);
student.setSname(sname);
student.setSage(sage);
return student;
}
});
for (int i = 0; i < query.size(); i++) {
Student student = query.get(i);
System.out.println(student);
}
System.out.println("-------------" + sql4 + "-------------");
//除了使用 RowMapper 做 query 的参数外,还可以使用 BeanPropertyRowMapper
List<Student> query1 = template.query(sql4, new BeanPropertyRowMapper<Student>(Student.class));
for (int i = 0; i < query1.size(); i++) {
Student student = query1.get(i);
System.out.println(student);
}
/* queryForObject:查询结果,将结果封装为对象
* 因为只返回1个对象,一般用于聚合函数的查询(使用Long.class)
* 当然也可以用于查找唯一值
*/
String sql5 = "select count(sno) from student";
System.out.println("-------------" + sql5 + "-------------");
Long total = template.queryForObject(sql5, Long.class);
System.out.println(total);
}
}